
一个帮你追踪最新AI应用的女子!
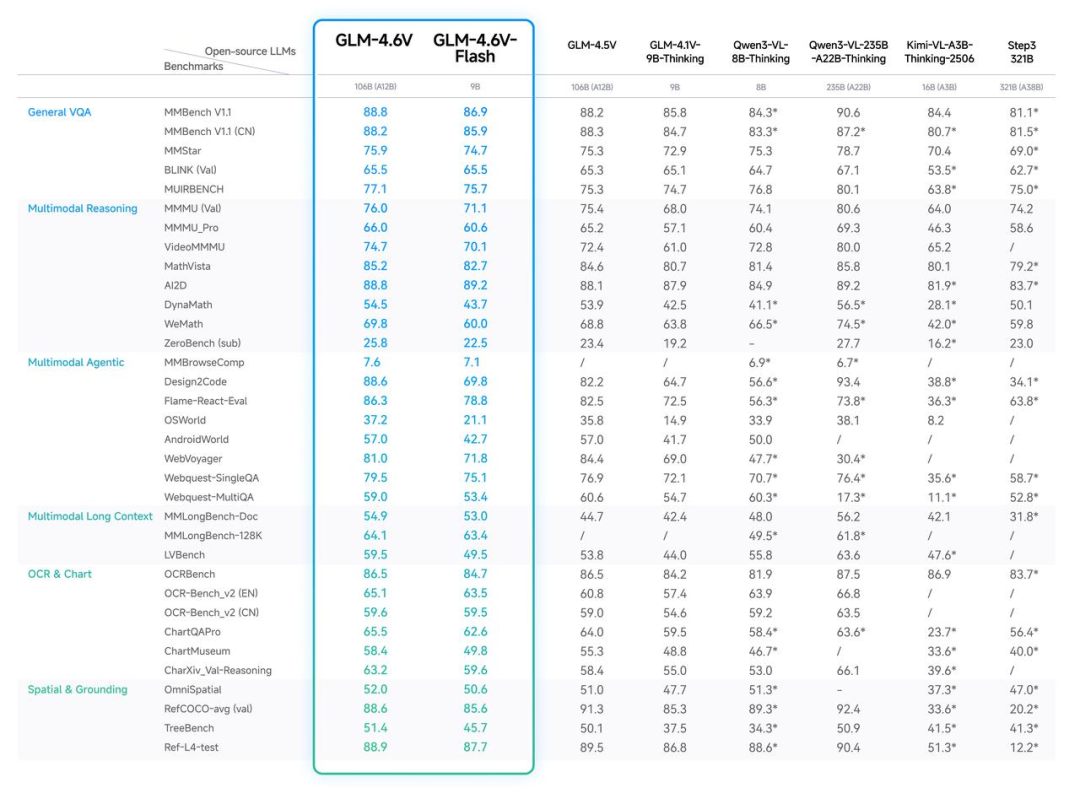
GLM-4.6V 系列模型,并全面开源!本次发布包含2个版本:
- GLM-4.6V:总参数量106B,单次推理激活参数约12B,视觉理解精度达到同参数SOTA,适合云端与高性能场景;
- GLM-4.6V-Flash:总参数量9B,更轻量,更快捷,适合本地部署;


https://chat.z.aiGitHub:
https://github.com/zai-org/GLM-VHugging Face:
https://huggingface.co/collections/zai-org/glm-46v
选择任一功能,GLM-4.6V 会自动调用匹配的工具。
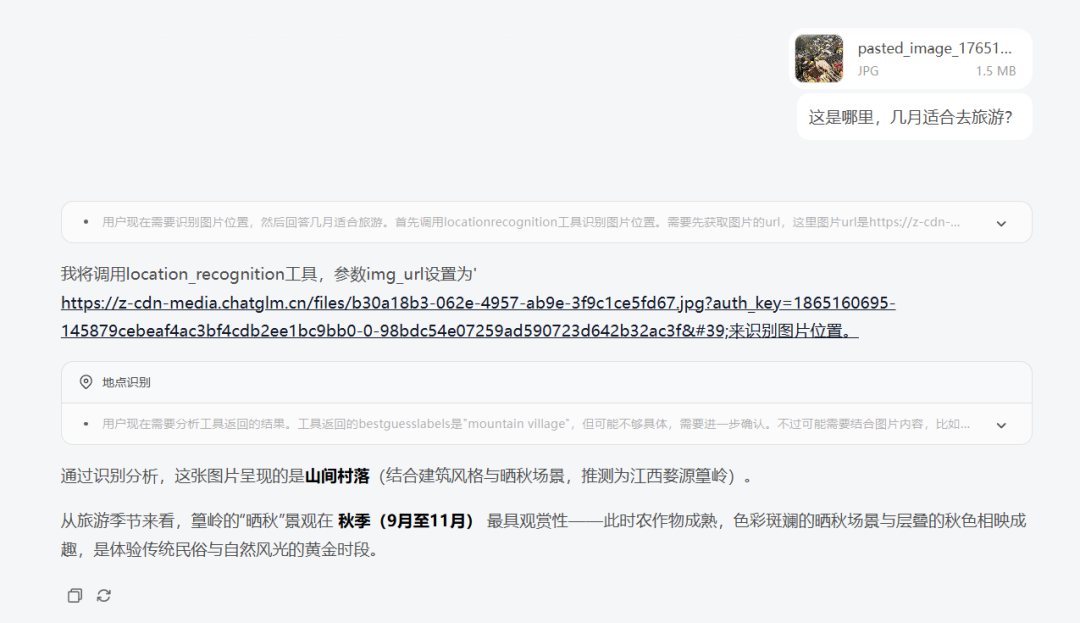
- case1 万能识搜

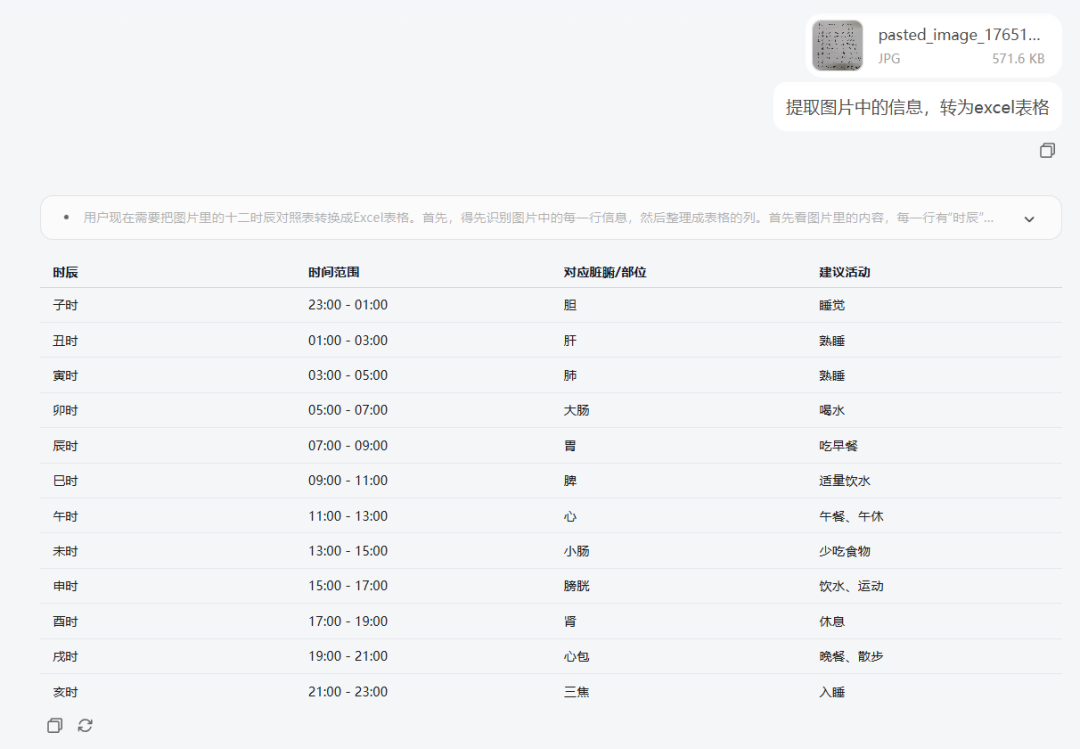
- case2 图文扫描


- case3 文档智读
GLM-4.6V 不仅能理解复杂的图表内容,还能把关键信息重新整理,用图文并茂的方式讲清楚。
- case4 视频理解
GLM-4.6V 给出的解读非常专业,整个视频讲述了什么内容,用了哪些镜头,这些镜头语言表达了什么情绪…比我理解的深刻多了。
- case5 数理解题
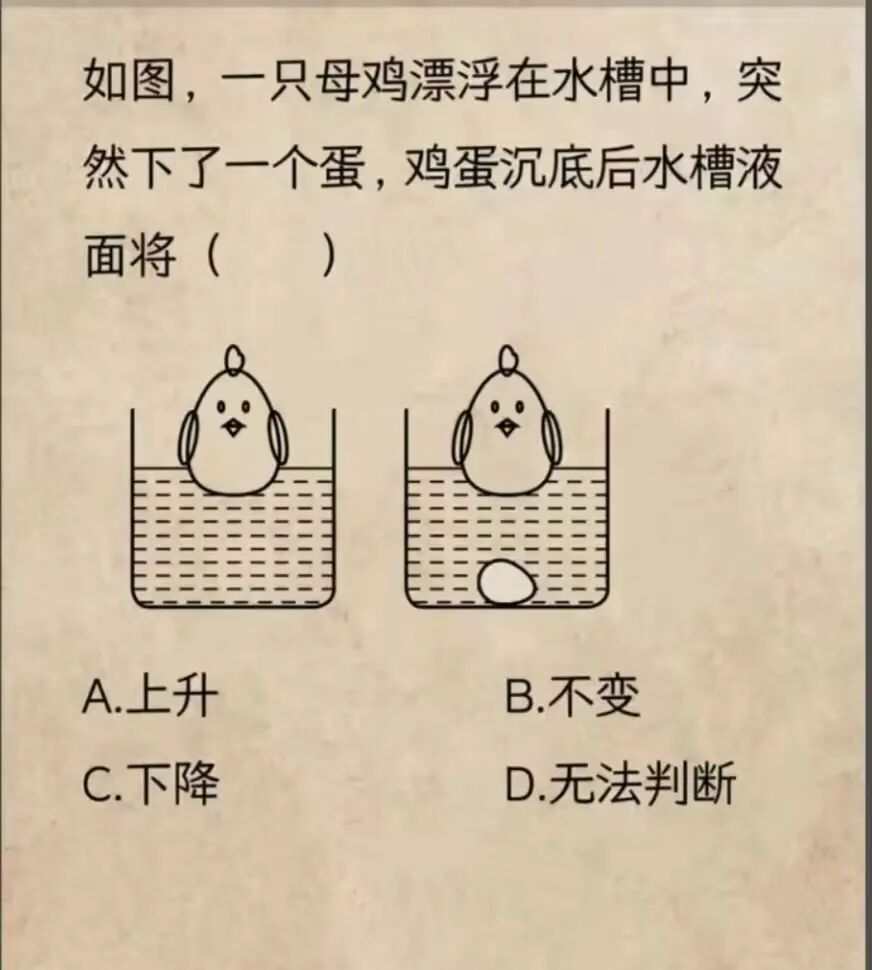

- case6 智能比价


- case7 图文内容创作
- case 8 复刻前端网页
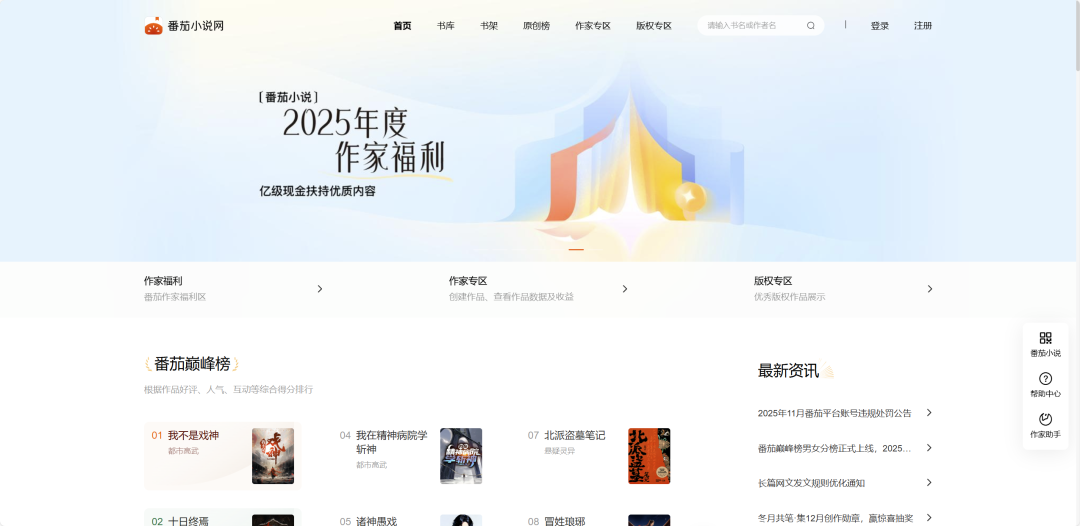

使用时,建议常开深度思考,模型回复质量会更高。前端复刻时建议关闭工具,其他情况下,根据任务自定义或者保持官方选项中的默认设置即可。这个强大的视觉能力还会融入到智谱的 Coding Plan,每个月最低只需要20元,可以直接使用最新模型能力,日常用非常香。随着这类能力逐步成熟,视觉信息将会深度参与决策、规划与行动本身,而现实世界的画面,都将成为系统可以直接理解和调用的一等信息源。视觉模型能力的提升,不只是给 AI 一双眼睛一双手,而是在为下一代智能体参与现实世界打开通道。未来的机器人不再需要被精确编程去执行某个动作,而是能够理解类似“去拿衣柜里最右侧的红色毛衣”这样的自然指令。
© 版权声明
文章版权归作者所有,未经允许请勿转载。