子工作流的核心特点:子工作流具有独立的执行环境,能够接收其他工作流传入的参数,并将处理结果返回给调用方。这使得同一个子工作流可以被多个父工作流调用,避免重复编写相同的逻辑。
这种设计模式带来了诸多优势:
-
模块化设计:将复杂的大型工作流拆分为更小、更易于管理的功能模块。
-
提高复用性:通用的功能(如数据清洗、发送标准格式的邮件、用户身份验证)可以封装成子工作流,在多个主流程中重复使用。
-
降低复杂度:主工作流的逻辑会变得非常简洁,只负责调用和编排各个子工作流,大大提高了可读性和可维护性。
-
解决性能问题:当工作流变得异常庞大时,可能会遇到内存限制等问题。将其拆分为多个子工作流可以有效缓解这种情况。
常见的应用场景包括:
-
数据验证与清洗:创建一个子工作流专门负责数据格式检查和标准化。
-
邮件发送:将邮件发送逻辑封装成子工作流,任何需要发邮件的父工作流都可以调用。
-
数据库操作:将复杂的数据库增删改查操作提取成子工作流。
-
第三方API交互:封装与外部服务的交互逻辑,统一管理调用方式。
-
错误处理与重试:创建通用的错误处理子工作流,提高系统稳定性。
1.2 )子工作流 和普通工作流的区别子工作流和普通工作流有什么区别?其实,从技术层面讲,子工作流就是一个普通的工作流,区别在于使用场景和设计思路。关键的区别体现在以下几个方面:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
二、创建第一个子工作流接下来,让我们通过一个简单的例子来实践一下。我们将创建一个子工作流,它的功能是接收一个名字,然后返回一句问候语,如 “Hello, [名字]”。实际操作步骤:第一步:创建子工作流
-
创建一个全新的工作流,可以将其命名为 “Sub: Say Hello”。

-
删除默认生成的触发器,点击
+号,在触发器列表中找到「When executed by another workflow」
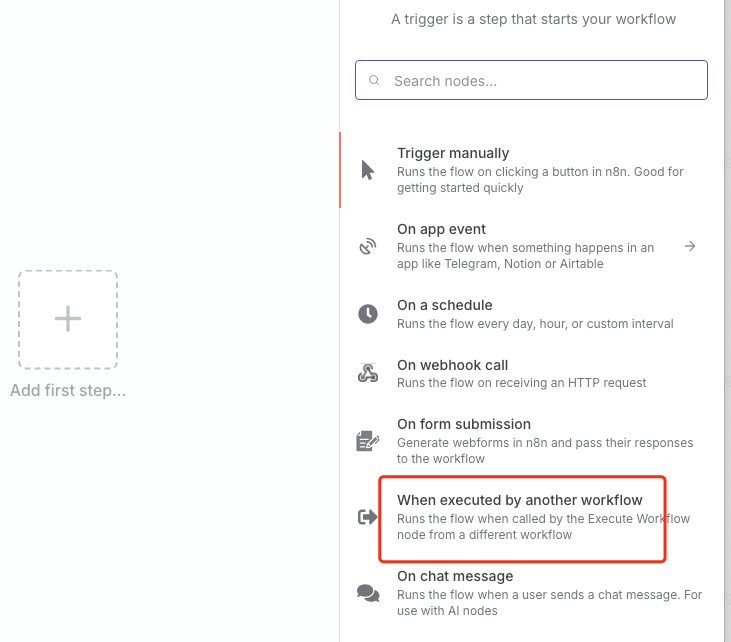
-
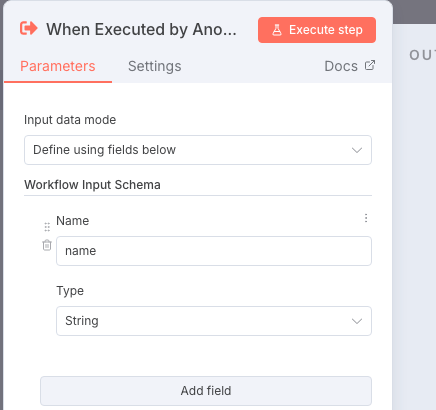
点击该节点,在「Input Data Mode」(输入数据模式)中选择
Define using fields below(使用下方字段定义)
在Inputs中,点击Add field,Name字段填写name,Type选择String。这代表我们的子工作流需要一个名为name的字符串类型输入。
-
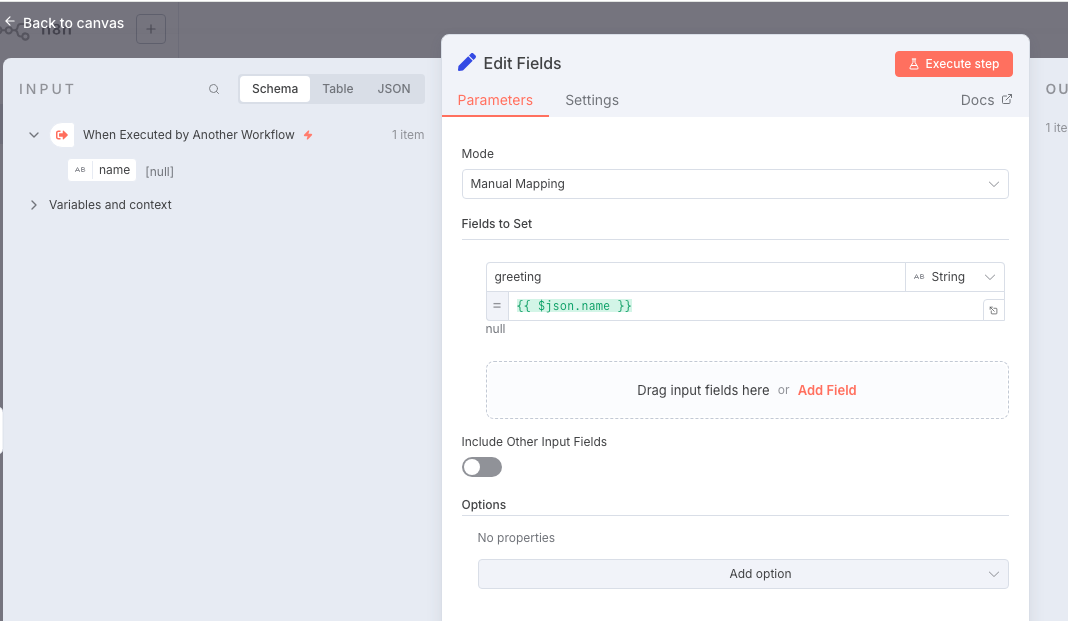
在
When executed by another workflow节点后面,添加一个
Set节点。
在Set节点中,将Name字段设置为greeting, Value字段填写表达式Hello, {{ $json.name }},
-
确保工作流已激活并
保存。一个包含错误的子工作流是无法被父工作流触发的。
第二步:创建父工作流来调用它
-
创建另一个新的工作流,命名为 「Main: Greet User」。
-
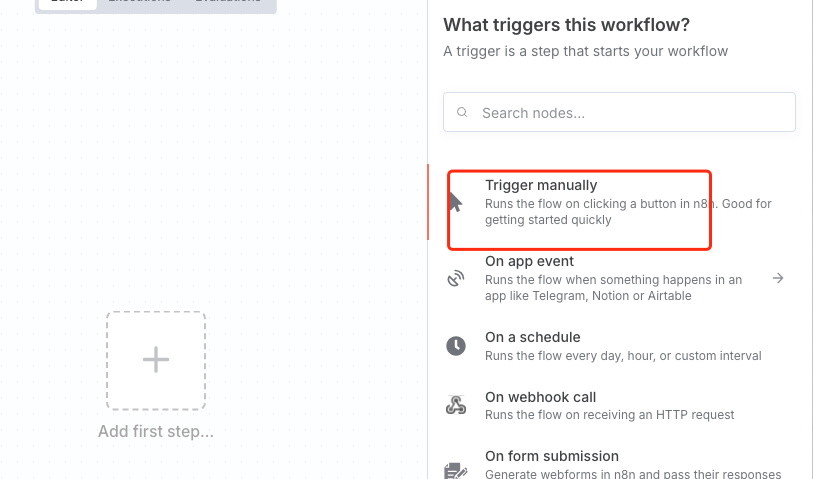
添加一个
Trigger manually
作为触发器,方便我们手动测试。
-
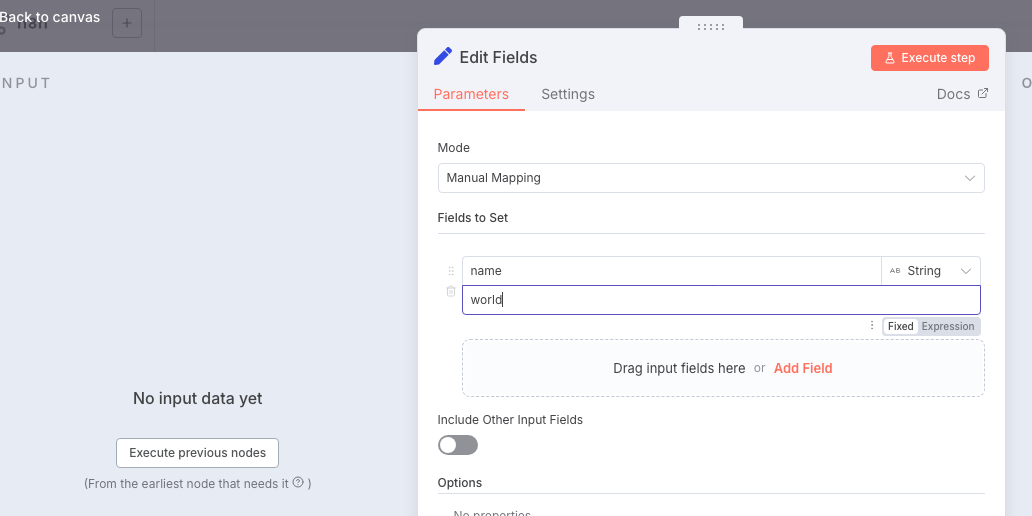
在触发器后添加一个
Set节点,用于准备要传递给子工作流的数据。将
Name字段设置为
name。在
Value字段填写一个名字,比如 「World」,
-
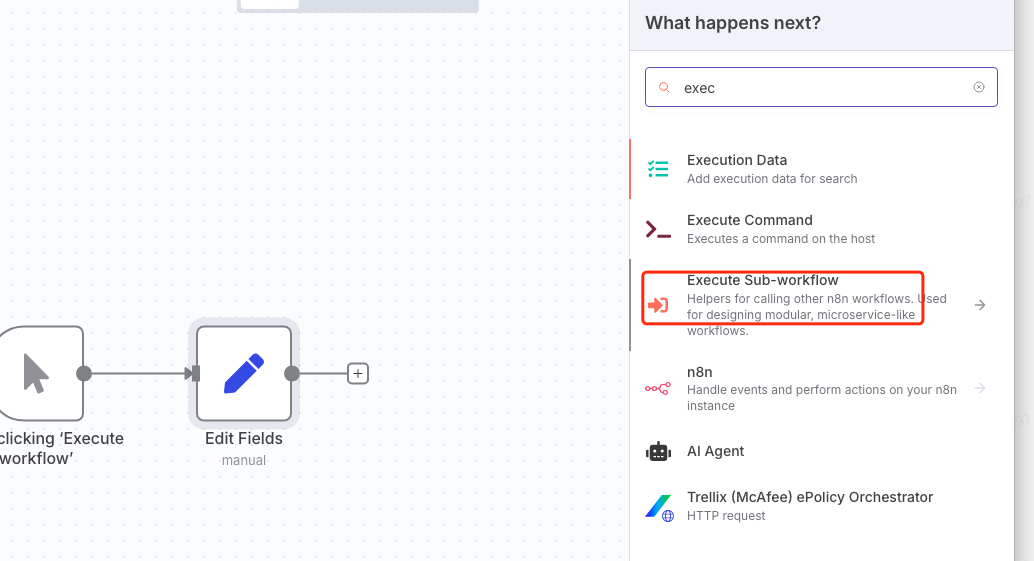
接着添加
Execute Sub-workflow节点。
-
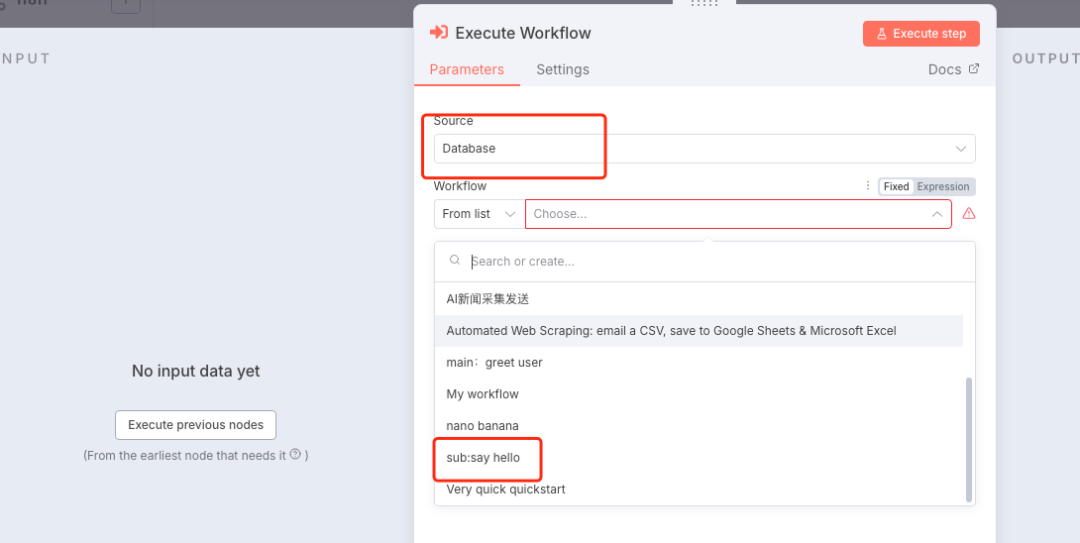
在
Execute Sub-workflow节点的
Source参数中,保持默认的
Database选项。 在
Workflow字段的下拉列表中,选择我们刚刚创建的 “Sub: Say Hello” 工作流。
-
n8n 会自动识别出子工作流需要的
name输入参数。我们可以使用表达式
{{ $json.name }}将上一个
Set节点的数据传递给它。
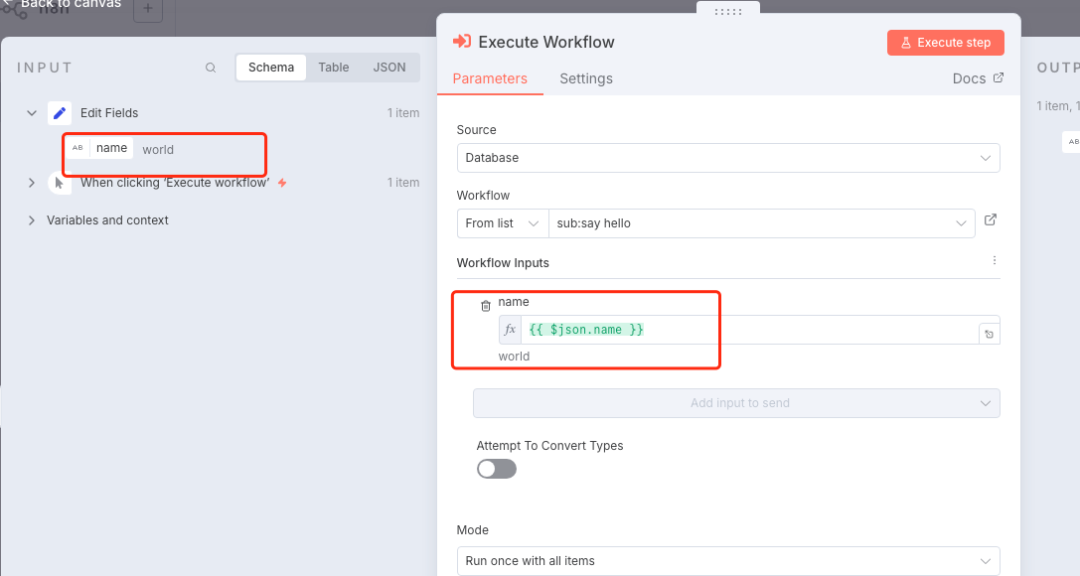
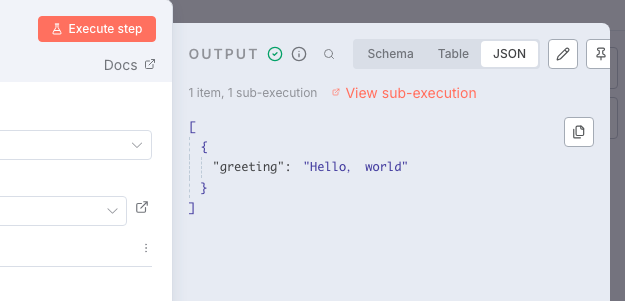
现在,在父工作流中点击 「Execute step」 运行Execute Sub-workflow节点。就会看到,它的输出结果正是来自子工作流中Set节点的数据:{ "greeting": "Hello, world" }。
三、参数传递数据的传入和传出是子工作流的核心机制3.1 输入参数配置如上例所示,子工作流通过When executed by another workflow节点来定义它需要接收的输入数据。它提供了三种模式:
-
Define using fields below:最常用的方式,可以明确定义每一个输入参数的名称和数据类型,清晰明了。
-
Define using
JSON
example:提供一个JSON样本,n8n会根据样本结构来推断输入格式。
-
Accept all data:不设任何限制,接收父工作流传来的所有数据。这种方式虽然灵活,但也要求子工作流内部能处理各种可能的输入情况。
在父工作流中,Execute Sub-workflow节点会相应地显示出这些需要填写的参数字段,我们通过表达式将数据传入即可3.2 输出结果返回子工作流的最后一个节点的输出数据,会作为Execute Sub-workflow节点的最终输出,返回给父工作流。父工作流可以接着使用这些返回的数据进行后续处理。返回节点允许你返回任何格式的数据——单个值、对象、数组或复杂的嵌套数据结构。返回数据时要考虑调用方的需求。确保返回的数据结构清晰明确,最好与之前定义的输入参数形成对应关系。例如,如果输入是一个包含多个字段的对象,输出也应该是一个结构化的对象。这样做的好处是让调用方可以更容易地解析和使用返回的数据,减少数据处理的复杂度。四、如何拆分复杂工作流4.1 拆分原则模块化设计的核心是单一职责原则。每个子工作流应该只负责一项特定的功能,不应该涉及多个不相关的业务逻辑。这样做有几个重要的好处。
-
子工作流更容易理解和维护。当查看一个工作流时,立即能够了解它的功能边界和实现逻辑。
-
高内聚、低耦合的设计使得子工作流具有更好的复用性。一个职责清晰的模块更容易被不同的场景引用,而多职责的模块往往有很强的上下文依赖,难以复用。
-
有利于错误定位和修复。当出现问题时,能够快速确定是哪个模块有问题,而不用在复杂的工作流中逐个排查。
拆分工作流的几个关键问题:这个工作流是否做了多个不相关的事情?有没有可以被其他工作流独立使用的逻辑块?这个工作流的流程是否过于复杂等等,如果是的话,最好考虑拆分。假设有一个复杂的订单处理工作流,负责处理订单。这个工作流集成了以下功能:从数据库查询订单信息、验证订单数据、计算订单总价、记录审计日志、发送邮件通知、更新数据库状态。这显然是一个违反单一职责原则的工作流。第一步:分析工作流的不同职责我们可以识别出以下几个独立的职责:订单数据验证、价格计算、邮件通知、数据库更新。第二步:创建子工作流创建「validate-order」子工作流,负责订单数据验证。创建「calculate-order-total」子工作流,负责价格计算。创建「send-notification-email」子工作流,负责发送邮件。创建「update-order-status」子工作流,负责更新订单状态。第三步:重构主工作流主工作流现在的职责被简化为:协调数据流。它调用各个子工作流,按照业务逻辑的顺序组织它们。这样重构后的好处是显而易见的。每个子工作流都可以独立测试和维护。如果需要修改订单验证逻辑,只需要修改一个地方。其他需要验证订单的工作流也可以复用这个子工作流。主工作流变得清晰简洁,主要展示业务流程。五、工作流复用5.1 多处调用同一子工作流工作流复用是子工作流最大的价值所在。 一旦你创建了一个功能稳定、通用的子工作流(如数据处理、API调用封装),就可以在任何需要此功能的地方通过Execute Sub-workflow节点来调用它。5.2 版本管理建议随着子工作流的不断增加,版本管理变得重要。n8n本身虽然没有内置的版本控制系统,但有一些最佳实践可以帮助你管理版本。在工作流名称中包含版本号。例如,可以命名为 「validate-email-v1」、「validate-email-v2」,当需要做破坏性的修改时,创建新版本而不是直接修改原有版本。这样可以确保已经依赖旧版本的工作流不会突然出错。保留足够的向后兼容性。在修改子工作流时,尽量保持输入参数的兼容性。如果必须改变参数结构,通过增加新参数而不是删除或重命名现有参数。维护一个文档说明各个版本的区别。在n8n中,你可以在工作流的「Notes」部分记录版本历史、功能改进和已知问题。5.3 最佳实践为了最大化子工作流的价值,这里总结几个最佳实践。
-
清晰的命名:为子工作流和参数使用一致的命名规范,最好使用前缀来分类,如「sub:validate-」、「sub:process-」、「sub:notify-」。这样可以让开发者快速理解工作流的功能。
-
保持独立与纯粹:子工作流应尽量保持无状态,不依赖于外部特定的执行环境,其所有需要的数据都应通过参数明确传入。
-
集中维护:将核心或常用逻辑封装成子工作流后,未来的修改和优化只需在这一处进行,所有调用方即可同步更新,高效且不易出错。
-
完善的文档和注释。为每个子工作流编写说明文档,包括功能描述、参数说明、返回值说明、可能的错误情况和处理方式。在工作流内部也要添加适当的注释,特别是复杂的Code节点。
-
健全的错误处理。子工作流应该具有完善的错误处理机制。对可能出现的异常进行捕获和处理,返回有意义的错误消息,帮助调用方快速定位问题。
六、总结子工作流是n8n中实现模块化设计的关键特性。通过将复杂的自动化流程分解为多个专一的子工作流,我们可以提高代码的可维护性、可复用性和可测试性。在实际应用中,记住要遵循单一职责原则,为子工作流设计清晰的输入输出接口,维护良好的文档和版本管理。这样,你就能有效地构建可扩展和易于维护的自动化系统。
© 版权声明
文章版权归作者所有,未经允许请勿转载。